漢字交じり文から精度良くタイピングワードを生成したい話
こんにちは。今回は自作タイプゲーに漢字交じり文からタイピングワードを生成する機能を付けた際に行った方法などを書いていこうと思います。
- 漢字交じり文からタイピングワードを生成するには
- 形態素解析とは
- 形態素解析サービスや種類について
- 自作ひらがな変換APIでタイピングゲームにひらがな変換機能を付ける
- 辞書データの変換ミスを修正したい
漢字交じり文からタイピングワードを生成するには
普通の漢字交じり文からタイピングワードを生成したい場合、皆さんはどのような方法が思い浮かぶでしょうか?
まず思い浮かぶのはWebにあるローマ字変換サービスを利用して、漢字からローマ字に変換する方法です。
https://hogehoge.tk/nihongo/#result

ローマ字に変換するとそのままタイピングワードとして利用できそうですが、日本語入力の場合は入力パターンが複数存在する関係上、タイピングゲームには流用しにくいかもしれません。
では、漢字交じり文からひらがなの文章に変換して、ひらがなの文章からローマ字の入力パターンを解析するようにするとどうでしょうか
漢字からひらがなに変換→ひらがなからローマ字(複数対応)に変換
'か' → ['ka', 'ca']など、ひらがなから対応する入力パターンに変換することで、複数の入力パターンにも対応することができました!
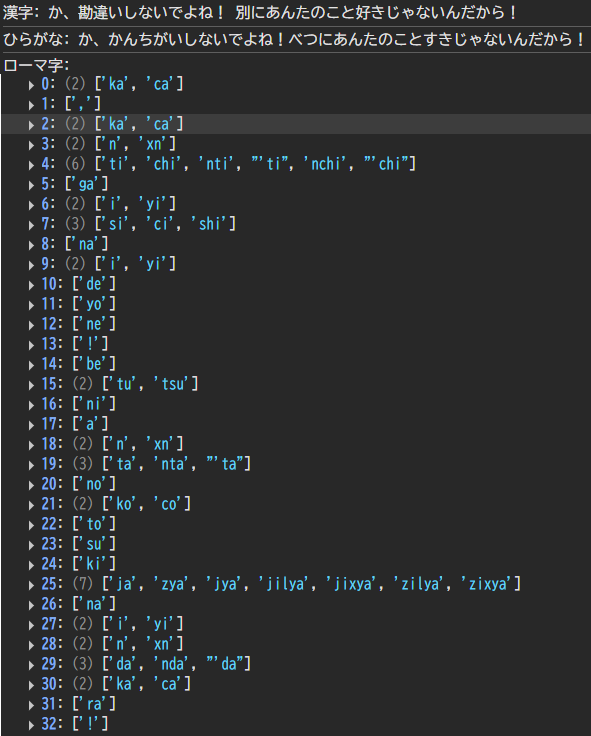
ひらがなから正確な入力パターンを生成できることが分かったので、漢字→ひらがなの変換を正確に行うことができれば、
漢字交じり文からタイピングワードを生成することができそうです。
形態素解析とは
漢字からひらがなに変換するには形態素解析という手法を用いることになります。
形態素解析(けいたいそかいせき、Morphological Analysis)とは、文法的な情報の注記の無い自然言語のテキストデータ(文)から、対象言語の文法や、辞書と呼ばれる単語の品詞等の情報にもとづき、形態素(Morpheme, おおまかにいえば、言語で意味を持つ最小単位)の列に分割し、それぞれの形態素の品詞等を判別する作業である。 wiki引用
実際に触ってみると分かりやすいと思います。以下のサイトで実際に形態素解析を行うことができます。
https://fugashi.streamlit.app/
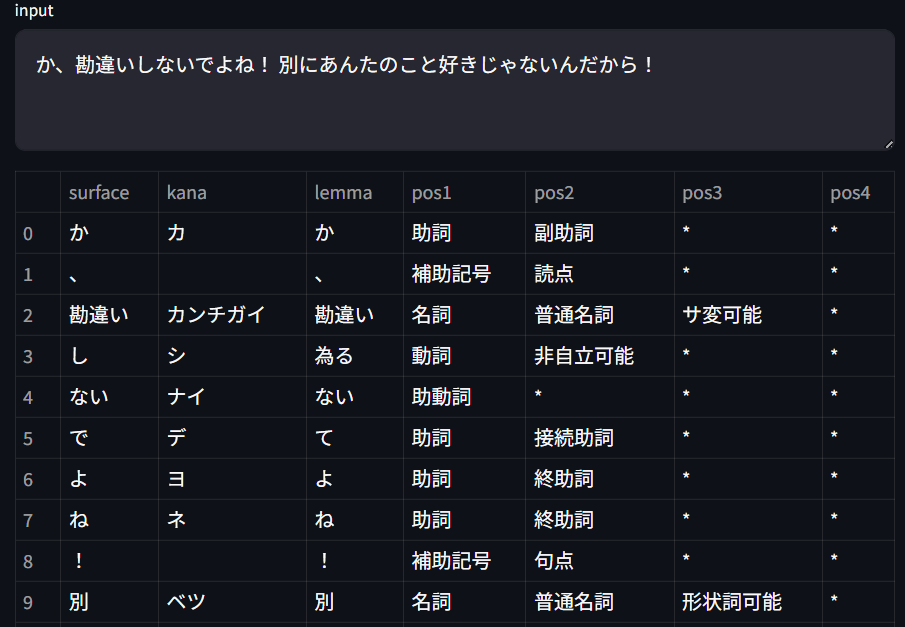
上記画像は実際に形態素解析してみた例です。
kanaの部分が読みの変換なので、kana列を連結してカタカナ→ひらがなに変換すれば漢字→ひらがなへの変換が完了する。という流れになっています。
形態素解析サービスや種類について
解析方法は分かったので、実際に変換ツールとして使用する場合にはどのような方法があるのでしょうか?
一番使いやすいツールとしては、前述の漢字→ローマ字変換サイトなどでしょう。こちらは手軽に利用することができる反面、実際に自作のタイピングゲームなどで漢字の文章群から高頻度にタイピングワードを生成したいといった場合にはタブやウィンドウを行き来する必要があるなど、手間がかかってしまうのがネックです。
そこで、形態素解析のサービスにはAPIで形態素解析機能を提供しているサービスがあるので、こちらを利用すると自作のタイピングゲームなどに漢字→ひらがな変換の機能を組み込む事ができるようになります。
形態素解析APIサービスについて
以下にAPIサービスをまとめました。
現在はYahooが提供しているサービスしかありませんが、こちらを利用すると自作のタイピングゲームなどに、簡単に漢字交じり文→ひらがな変換機能を付けることができます。
形態素解析APIサービス | 変換精度 | 運営 |
|---|---|---|
◯ | サービス終了 (2025/3/26) | |
△ | サービス公開中 (2025/4現在) |
最初、私はgooラボの形態素解析サービスを利用していましたが、こちらのサービスは中々変換精度も良く、サービスを利用するためのAPIキーを取得すれば、ひらがなに変換したい漢字交じり文をgooラボのURLに送信するだけで、精度の良いひらがなの文章を返してくれるのでかなり重宝していましたが、2025/3/26に突然サービス終了してしまい利用できなくなってしまいました。。。
取り急ぎ、Yahoo日本語形態素解析APIに乗り換えましたが、こちらはかなり古い解析辞書を使用しているのか、40%ぐらいの頻度でひらがなの変換ミスが起きてしまい、ワードの見直しにかなりエネルギーを要することになってしまう事態になりました。
変換精度をどうにか改善できないか色々と調べていると、自前で形態素解析APIを用意できるらしく、解析に使用する辞書も最新のものを使用できるとのことで、分からないなりに試しに作成してみることにしました。
形態素解析APIを自前で用意
形態素解析は辞書データと提供されている解析器プログラムがあれば、自分のPCからオフライン上で解析できたり、汎用的に使用できるようで、Google Cloud FunctionやらAWS LambdaというURLから自分の作成したプログラムを呼び出せるサービスと連携すると、自前で形態素解析APIサービスを作ることができます。自作APIを作るにあたりメジャーな辞書&解析器プログラムを以下に記載しました。
辞書データ&解析器 | 変換精度 | 認知度 | 辞書最終更新日 |
|---|---|---|---|
mecab-ipadic-neologd | △ | ◎ | 2020/09/10 |
Juman++ | ◎ | △ | 2017/1/12 |
Fugashi Unidic | ◯ | ◯ | 2023/2/? |
Sudachi | ◯ | ◯ | 2025/1/29 (2025/4/19現在) |
最初は自前でAPIを用意する導入記事の大半がmecab-ipadic-neologdを使用していたのでこちらを採用しようと思いましたが、mecab-ipadic-neologdはWeb上でスクレイピング?して単語を集めて作られているらしく、ひらがな変換器として使用する場合に変換精度が低いらしいので見送り。
Juman++は基本語彙(約3万語)を人手で整備しているようで、変換精度はかなり良さそうでしたが辞書の形式が他3つとは違うらしく変換速度が遅い&環境構築がうまくできなかったので見送り。
色々試して見た結果Sudachiが一番速度と精度のバランスが良さそうなのでSudachiを採用しました。
なんやかんやAWSを弄りまわして(省略)、なんとか自前でひらがな変換APIを作成できました。

形態素解析で単語毎に分割された状態でひらがな変換結果を返すようにしています。そのままひらがなの文字列を返すようにしてもよかったのですが、後述の辞書データの変換ミスを修正したいで単語毎に分割する必要があったので、このように変換結果を返しています。
辞書データの変換ミスを修正したい
最新のSudachi辞書でひらがな変換を行うようにしたことで、変換精度はYahooのAPIの頃に比べて劇的に向上したのですが、タイピングデータを作成しているとまだまだ平仮名の変換ミスは散見されます。
このセクションでは辞書の変換ミスをどのように修正するか考えて行こうと思います。
たとえばタイピングワードに変換したい文章に「私」という代名詞を含めてひらがな変換しようとすると、辞書データでは「私」→「わたくし」に変換されるように設定されているので、どんな文章でも必ず「わたくし」と平仮名変換されてしまいます。
前述の形態素解析デモでも一般的に活用する頻度が低い「わたくし」と変換されるのを確認できます。
読み方の頻度としては「わたし」の方が多いので「わたくし」ではなく「わたし」に変換されるように修正を行いたいです。
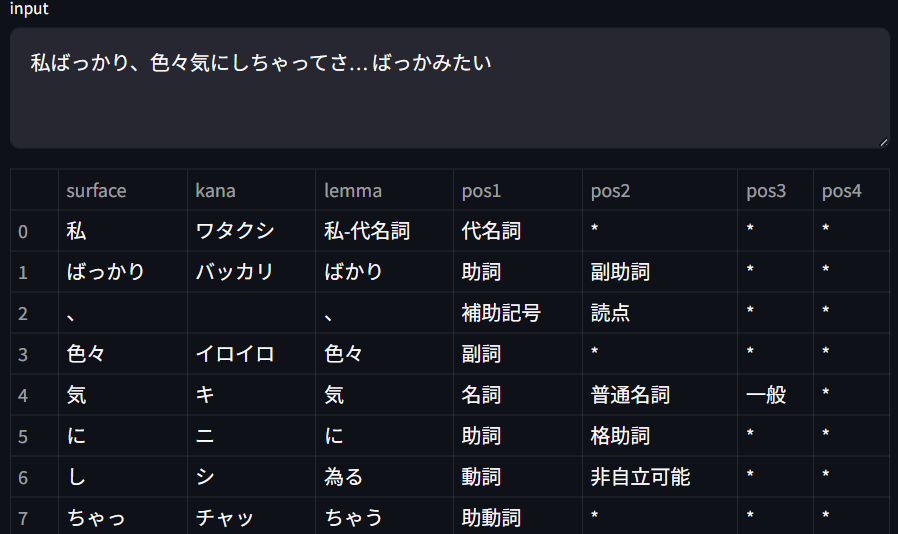
修正案としては以下の方法を試したので解説します。
・Sudachiのユーザー辞書機能を使用して修正する方法
・タイプゲーのDBに修正したい単語を登録して修正する方法
Sudachiのユーザー辞書機能を使用して修正する方法
最初にこちらの方法を試しましたが、以下の問題が浮上したので断念しました。。
・「私」→「わたし」に変換されるようにユーザー辞書に登録した結果、「私語」「私案」などの熟語も「わたしご」「わたしあん」などに変換されるようになってしまう
・上記の点を踏まえると「私」→「わたし」に変換されるようにするには「私は」「私を」「私に」などの単位で登録すると良いですが、対応範囲が多くなりすぎてカバーしにくい
・ユーザー辞書を更新する度にAPIの更新が必要になり、更新に時間がかかる
「私語」「私案」など修正したくない単語にまで適用されてしまう問題が特に大きいのでユーザー辞書での修正方法は断念しました。(自分のユーザー辞書の書き方に問題がある可能性はあるのでまたリベンジしたい)
タイプゲーのDBに修正したい単語を登録して修正する方法
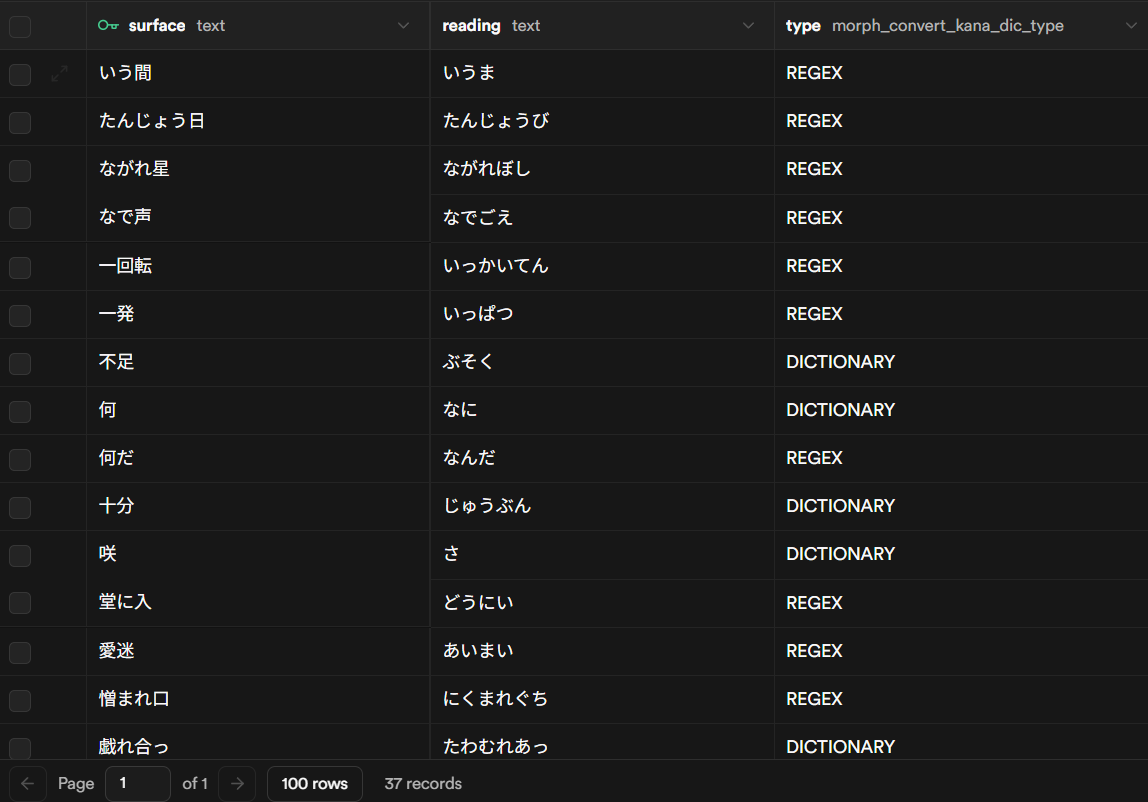
タイプゲーのDBに以下の画像のように漢字と平仮名を登録して、変換時にDBに登録されている単語を優先的にひらがな変換する方法です。
こちらの方法はTypingTubeでも採用されていました(現在は登録機能は廃止されている?ようです)
画像の右側のREGEXが指定されている単語は形態素解析APIに送信する前に変換が必要な単語。
DICTIONARYは形態素解析完了後の単語単位で区切られている状態のときに変換する単語です。
「私」→「わたし」をDICTIONARYで登録すると正常に代名詞の「私」の読みのみを修正することができます。
問題は変換失敗する単語をどのように炙り出すかですが、TypingTubeであったようなユーザーが平仮名変換ミスを見つけた時に自ら辞書テーブルに登録できる機能をタイプゲーに付けた場合、ユーザーによっては間違えた方法で登録してしまったり、最悪の場合荒らしにより、正常な単語が変換されなくなるように変更されてしまう恐れがあるので、断念しました。
別の方法として、ユーザーが手動で読みを修正した場合にDBに修正前のタイピングワードの漢字交じり文と平仮名のセットのログを取るようにし、単語の修正はそのログを見て自ら随時行うようにしました。
左:漢字交じり文 | 右:平仮名文 (修正前)
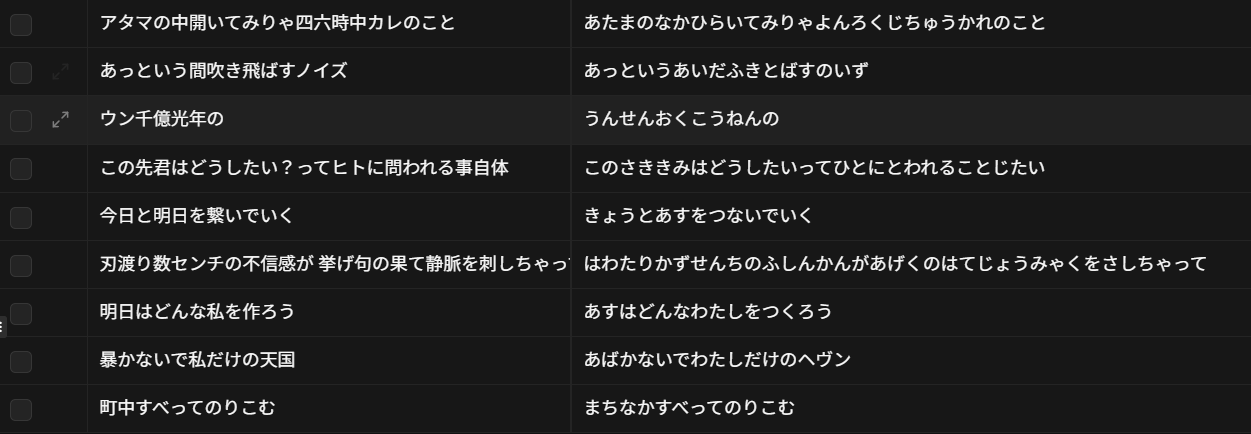
ログを見てみると「四六時中」→「よんろくじちゅう」「あっという間」→「あっというあいだ」のように間違えて変換されてしまっているので、この単語をDBの辞書テーブルに登録していきます。
ほとんどの単語はこの方法で修正対応することができそうですが、中には読み方が複数あったり(「明日」→「あす、あした」など)、修正が困難な単語もあるので、平仮名変換後のワードの見直しはまだまだ必要はありそうです。。。
終わり
結果として、以前よりはかなり精度良くタイピングワード生成ができるようになりました。読み修正が必要ない場合も結構あります。
ですが当て字や読み方が複数ある漢字などは適切な変換が難しいのでまだまだひらがな変換後の確認作業は必要そうです。
久々に長い文章を書いて疲れたのでこれぐらいで、
ここまで読んでいただきありがとうございました。